0. 前言
- 本文记录遇到的GPU/CUDA相关的操作。
- example(把文末的样例放到前面来,方便自己复制……)
1 | import os |
1. CUDA
1.1. 安装CUDA以及CUDNN
- 安装CUDA:
- cuda下载链接
- 这里选择 linux - x84_64 - ubuntu - 16.04 - runfile(local)
- 在下载连接后有教怎么安装:
- 安装命令
sudo sh cuda_10.1.105_418.39_linux.run。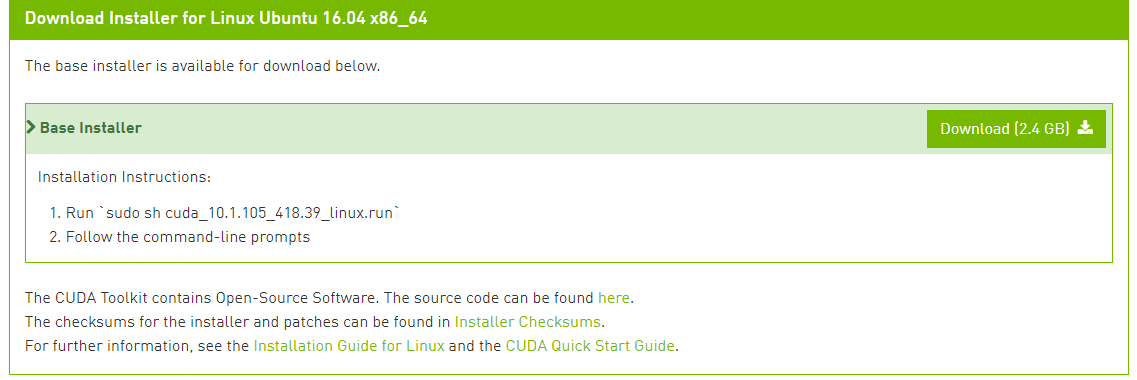
- 安装命令
- 将相关
lib64目录添加到环境变量LD_LIBRARY_PATH中。
- 安装cudnn
1.2. 多个版本CUDA的切换
- 参考资料:CSDN
- 主要思路:在第二个CUDA时,安装选项
Do you want to install a symbolic link at /usr/local/cuda?应该看情况选no。 - 切换CUDA版本的本质就是修改
/usr/local/cuda的软连接,使其链接到我们想要的cuda版本中。 - 修改软连接相关命令:
1
2
3sudo rm -rf /usr/local/cuda
sudo ln -s /usr/local/cuda-9.0 /usr/local/cuda
nvcc --version
1.3. 同一台电脑上多个CUDA版本多个TF版本
- 碰到的问题:因为一台服务器只有一个默认的cuda版本,所以在安装不同TF版本时往往会报错。
- 例如,tf 1.13.1 需要 cuda 10.0,而 tf 2.0 beta 需要 cuda 10.1 。
- 解决思路一(参考资料):
- 由于不同版本中cuda对应的
lib64中文件名均与版本相关,所以可以直接将不同版本cuda的lib64文件夹保存到LD_LIBRARY_PATH中。 - 举例:
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64:/usr/local/cuda-10.1/lib64:$LD_LIBRARY_PATH
- 由于不同版本中cuda对应的
- 解决思路二(参考资料):
- 可以通过conda来实现。
- conda提供一个功能:在进入/退出conda环境时,可以通过设置运行脚本,从而控制系统变量等。
- 脚本名称:
/<path to anaconda>/envs/<env name>/etc/conda/activate.d//<path to conda>/envs/<env name>/etc/conda/deactivate.d/
- 在
activate.sh和deactivate.sh中添加1
2
3
4
5
6
7
8
9# activate.sh
#!/bin/sh
ORIGINAL_LD_LIBRARY_PATH=$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/usr/local/cuda-version/lib64:$LD_LIBRARY_PATH
# deactivate.sh
#!/bin/sh
export LD_LIBRARY_PATH=$ORIGINAL_LD_LIBRARY_PATH
unset ORIGINAL_LD_LIBRARY_PATH
1.4. 查看已经安装好的CUDA以及CUDNN版本:
- 查看cuda版本:
cat /usr/local/cuda/version.txt - 查看cudnn版本:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
1.5. 查看显卡算力
- 官方链接
- 1080Ti / Tesla P4 / Tesla P40 都是 6.1。
- 1080Ti / Tesla P4 / Tesla P40 都是 6.1。
1.6. CUDA 命令
nvidia-smiGPU: GPU编号,如图中的0, 1, 2, 3。Name: GPU型号,如图中的 Tesla P40。Persistance-M: 持续模式的状态,如图中的Off状态。- 持续模式的能耗大,但在启动新的GPU应用时,花费时间更少。
Fan: 风扇转速,取值从0%到100%。Temp: 显卡温度,单位为摄氏度。Perf: 性能状态,从P0到P12。- P0代表性能最大(未工作时为P90,达到最大工作限制时为P12)。
Pwr:Usage/Cap: 能耗,分别表示当前能耗和能耗上限,如图中的 49W 和 250W。Bus-Id: 总线相关,不太懂,格式为 domain:bus:device.function。Disp.A:Display Active,GPU显示是否初始化。Memory-Usage: 显存使用率。Uncoor. ECC: Error Correcting Code,是否开启错误检查和纠正技术。Volatile GPU-Utils: 浮动GPU使用率。Compute M.: Compute mode,计算模式,0/DEFAULT,1/EXCLUSIVE_PROCESS,2/PROHIBITED。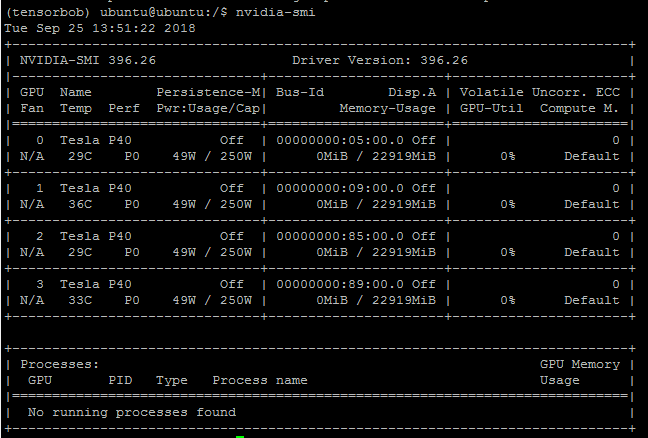
nvidia-smi -L- 查看可用GPU列表。

- 查看可用GPU列表。
2. GPU
2.1. 环境变量
- 环境变量名称
CUDA_VISIBLE_DEVICES。 - Python下设置格式:
- 不使用任何GPU:
os.environ["CUDA_VISIBLE_DEVICES"]="" - 使用单个GPU:
os.environ["CUDA_VISIBLE_DEVICES"]="0" - 使用多个GPU:
os.environ["CUDA_VISIBLE_DEVICES"]="0,1"
- 不使用任何GPU:
- 一般要配合
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"一起使用。- 原因可以查询 issue 152
- 关于GPU的编号:
- 不管
CUDA_VISIBLE_DEVICES中选择的GPU型号是从多少开始,tf.device中的编号都是从0开始的。 - 如
os.environ["CUDA_VISIBLE_DEVICES"]="1",在python中也要使用tf.device('/gpu:0')来使用GPU。
- 不管
2.2. tf.ConfigProto 配置
- 创建 Session 时可以导入配置文件
tf.ConfigProto(),下面介绍该配置文件中内容。 - 该 protobuf 文件源码可以参考 tensorflow/tensorflow/core/protobuf/config.proto。
ConfigProto内容如下。map<string, int32> device_count:设置每类设备(CPU, GPU)的最大数量。- 通过这个参数设置GPU数量,显存照样占用,不知道咋回事。
int32 inter_op_parallelism_threads:设置多个操作并行运算线程数量。int32 intra_op_parallelism_threads:设置一个操作内部并行运算的线程数量,0为最优线程数。bool use_per_session_threads:已经Deprecated了- 英文文档翻译:近在单线程时有效,如果为True则新建一个线程池,而不是使用全局线程池。
repeated ThreadPoolOptionProto session_inter_op_thread_poolint32 placement_periodrepeated string device_filtersGPUOptions gpu_options:GPU相关设置,参考下面。bool allow_soft_placement:运行设备不满足要求时,自动分配GPU或CPU。- GPU上不能完成的设备是否需要转移到CPU上。
- 也有其他解释:如果你指定的设备不存在,允许TF自动分配设备。
bool log_device_placement:是否观察每个运算所用的设备。- 若设置为 True,则在运行后会显示。
- 好像在jupyter notebook上看不到,但在运行脚本时可以看到。
GraphOptions graph_options:计算图设置,不是GPU配置重点,暂不研究。int64 operation_timeout_in_msRPCOptions rpc_optionsClusterDef cluster_defbool isolate_session_stateExperimental experimental
GPUOptions内容如下。double per_process_gpu_memory_fraction:显存最大占用比例。bool allow_growth:是否按需分配显存。string allocator_typeint64 deferred_deletion_bytesstring visible_device_list:在 visible 的GPU中进行编号映射。- 如将编号为5的GPU映射为
/gpu:0,编号为2的GPU映射为/gpu:1,则该字段应该对应为5,2。 - 这里GPU的编号,指的是经过
CUDA_VISIBLE_DEVICES之后GPU的编号,而不是nvidia-smi中GPU的编号。
- 如将编号为5的GPU映射为
int32 polling_active_delay_usecsint32 polling_inactive_delay_msecsbool force_gpu_compatibleExperimental experimental
2.3. example
1 | import os |