0. 前言
- 来自 Yolo v2 的 Better 章节。
- lars76/kmeans-anchor-boxes
1. 论文内容总结
1.1. 引入
- 在Yolo v2中借鉴了Faster R-CNN,引入了anchors的概念。
- 引入Anchors是为了更好的预测bbox的定位信息,即
x, y, w, h。 - 但对于anchors的选择,Yolo v2选择了与Faster R-CNN不同的方法:
- Faster R-CNN中,anchors根据边长、长宽比例选择了,论文中认为这是“手动选择”。
- Yolo v2认为可以选择更好的先验bbox,即使用 kmeans 选择。
1.2. 论文配图
- 左边的图:
- 当选择k个先验框时,数据集中所有bbox的平均IOU。
- 横坐标表示要选择的anchors数量,纵坐标表示平均IOU。
- 蓝色的是COCO,黑色的是VOC2007。
- 选择k值为5,这是性能与模型复杂度之间平衡的结果。
- 右边的图:
- kmeans 选出的候选框。
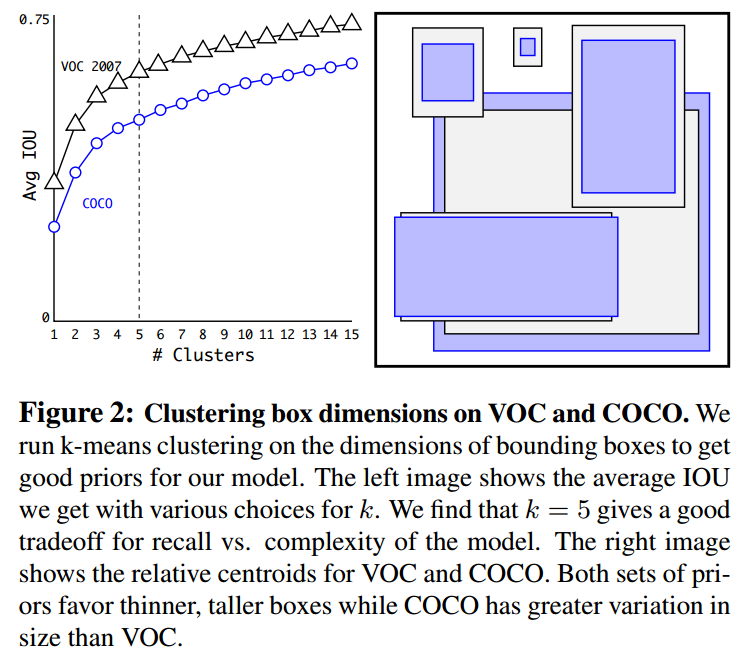
- kmeans 选出的候选框。
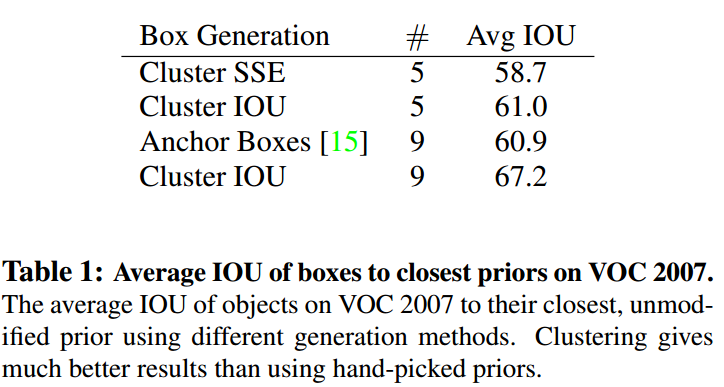
1.3. 效果
- 表中的四行分别代表:
- Cluster SSE:猜测使用欧几里德距离的聚类。
- Cluster IOU:使用IOU作为距离的聚类。
- Anchor Boxes:普通Anchors。
- 结果解释:
- 5个聚类选出的候选框效果与9个手动选择的候选框效果差不多。
- 9个聚类选出的候选框效果远远好于9个手动选择的候选框。
2. 实现
2.1. 基本概念
- 聚类要获取的是bbox的长与宽两个参数。
- 距离:
- 两个bbox的距离,先计算两个bbox的IOU,在通过
1-IOU作为距离。 - 可以这么想象:假设两个bbox的一个叫对齐,然后计算IOU。
- 两个bbox的距离,先计算两个bbox的IOU,在通过
- 代码参考 这里
2.2. 总体流程
- 第一步:获取数据集中所有bbox的长与宽。
- 第二步:从数据集的bbox中随机选择k个作为初始
中心bbox。 - 第三步:计算
其他bbox与中心bbox之间的距离,即1-IOU。 - 第四步:根据上述距离进行聚类,即将
其他bbox归类到与其距离最小的中心bbox中。换句话说,将所有bbox分为k类。 - 第五步:对于每一类bbox,计算通过平均数/中位数获取k个bbox,作为新一轮的
中心bbox。 - 第六步:重复第三到第五步,直到前后两次获取的
中心bbox完全相同为止。