0. 前言
- 本文主要包括两部分内容:
- 第一部分:介绍Yolo v1/v2/v3 三篇论文的主要内容。
- 第二部分:介绍DarkNet的使用。
1. 论文笔记
- 论文:
1.1. Yolo v1
- 参考资料:
- 素质四连
- 要解决什么问题?
- 对于物体检测任务,快速算法的性能低;性能高的算法(如R-CNN系)不能达到实时性的要求。
- 之前物体检测任务主要分为两个步骤,第一步获取候选区域,第二步队每个分区进行分类。这种方法的性能不能达到实时性要求。
- 用了什么方法解决?
- 提出了一种使用回归方式获取候选去的方法,将所有物体检测任务都结合到一个神经网络中。
- 效果如何?
- 运行速度大大提高,可以达到45fps。
- 相比于其他快速物体检测模型,检测结果的准确率有了很大提高。
- 相比于R-CNN,对于背景的分类结果好了很多。
- 还存在什么问题?
- 模型准确率距离其他模型(如Fast R-CNN)还有一定的距离。
- 在候选边框预测方面(与R-CNN系方法相比),误差较大且对于新数据集的泛化能力较弱。
- 对于空间聚集较密的数据的预测结果不好。
- 要解决什么问题?
- Yolo 系统结构如下:
- 第一步,resize图片。
- 第二步,进行图像检测,获取若干候选框以及对应的类别。
- 第三步,通过NMS筛选第二步得到的候选框。

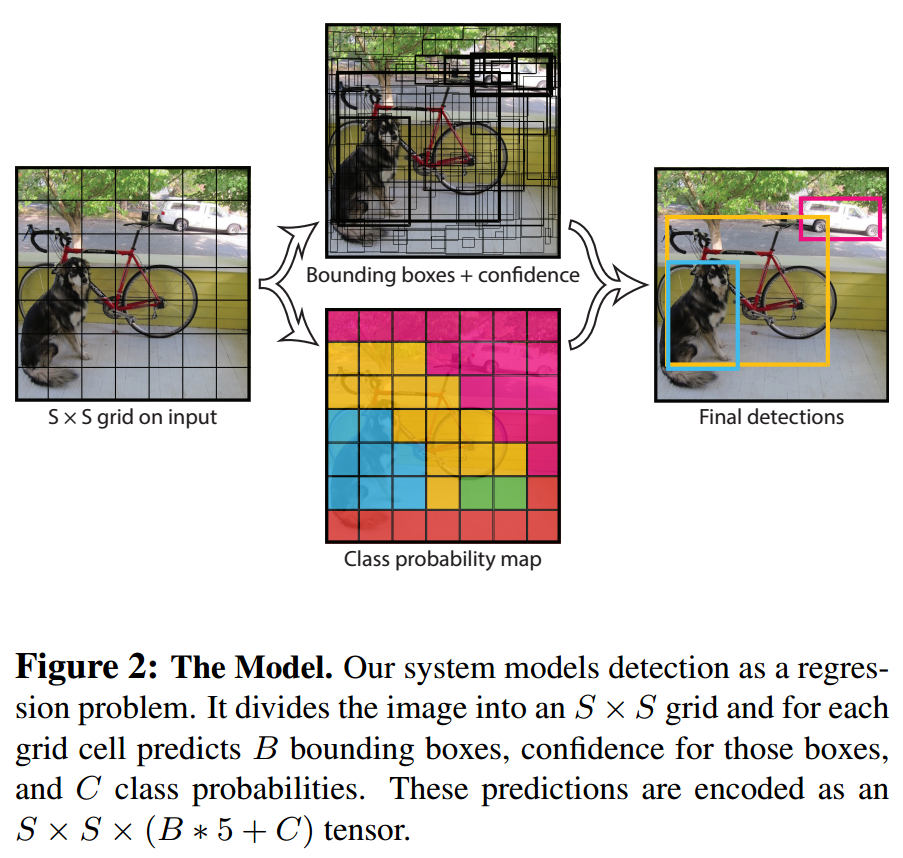
- Yolo 模型思路如下图:
- 第一步:将图片分为SS个区域,其实就是经过backbone获取SS的特征图。
- 第二步:通过全连接、卷积等操作,获取
S*S特征图中每个点的图像检测信息。每个点一共分类依稀和预测B个bbox,分类信息是个长度为C的向量,每个bbox预测长度为5的向量,所以预测每个点要预测的向量长度为S*S*(B*5+C)。 - 第三步:进行 post-processing 筛选获取的bbox。
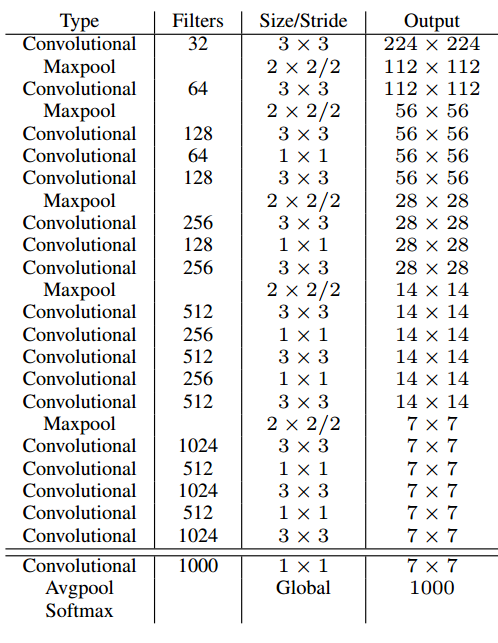
- Yolo 网络结构如下图:
- 网络结构没什么好说的,就提一下中间有全连接层……

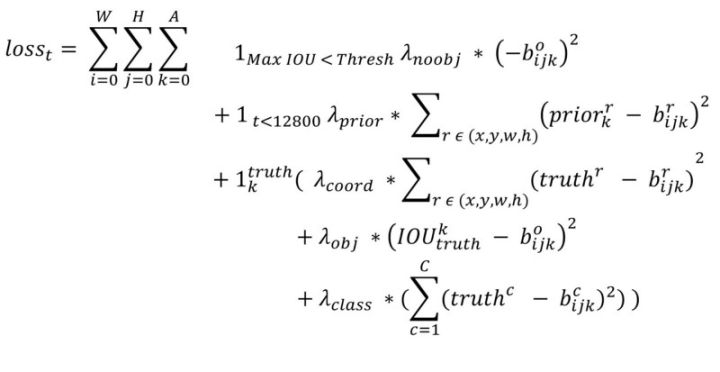
- Yolo 损失函数如下图:
- TODO:参考 源码 进一步理解Yolo loss。
- 首先,对于Yolo中所有损失函数都是以平方差的形式存在。
- 几个解释:
- $1_i^{obj}$ 代表网格中存在对象,但不确定是哪个bbox。
- $1_{ij}^{obj}$ 代表网格i中第j个bbox存在对象。
- $1_{ij}^{noobj}$ 代表网格i中的j个bbox不存在对象。
- 几个 $\lambda$ 都是为了平衡大小。
- 猜测上述内容的计算流程:
- 第一步:根据gt获取所有有物体的bbox对应的中心点,即选择S*S中的某一个点。
- 第二步:分别计算GT bbox与选中点中B个候选bbox之间的IOU。
- 第三步:选择IOU较大的候选bbox作为 $1_{ij}^{obj}$。
- 第四步:遍历所有GT bbox,除了选中的候选bbox外,其他的均作为 $1_{ij}^{noobj}$。
- 损失函数分为三个部分:
- 通过confidence计算损失函数(判断是否有物体)
- 对应下图中第三行与第四行。
- 对所有候选bbox都进行计算。
- 分类误差(确定有物体,判断物体类别)
- 对应下图中第五行。
- 只对确定有物体的bbox进行计算。
- 物体bbox误差(确定有物体,计算x, y, w, h的误差)
- 对应下图中第一行与第二行。
- 只对确定有物体的bbox进行计算。

- 通过confidence计算损失函数(判断是否有物体)
1.2. Yolo v2
- 参考资料:
- 素质四连
- 要解决什么问题?
- YOLO v1性能不好,与Faster RCNN的主要区别在于定位误差大,且召回率低。
- 图像分类数据集较容易获取,数据量多,分类种类也多;物体检测数据集获取难度较大,分类种类太少,无法像数据分类数据集那么丰富。
- 大多数检测模型只能用于某个特定数据集。 most detection methods are still constrained to a small set of objections.
- 用了什么方法解决?
- 从 Better, Faster, Stronger 三个角度对原有的YOLO模型进行优化。详细内容下文再说。
- 效果如何?
- 在VOC COCO上达到了state-of-the-art的检测结果。
- 训练了YOLO9000模型可用于检测超过9000类物体。
- 达到实时性要求。
- 还存在什么问题?
- 这一系列的方法(YOLO SSD YOLO v2)都对小物体、聚集在一起的多个物体的检测结果不佳。
- 要解决什么问题?
- Better(基于v1提高模型性能)
- Batch Normolization: 在网络中添加BN。
- High Resolution Classifier: 提高输入图片的尺寸:v1是224224,v2中用448448。
- PS:训练的时候,先用448*448的模型在ImageNet上训练10个epochs,然后再用于目标检测训练。
- Convolutional with Anchor Boxes & Dimension Clusters: 引入anchors,且利用聚类获取先验边框信息。
- Direct location prediction: Faster RCNN中bbox的预测形式会导致预测不稳定,所以使用了类似yolov1的bbox表现形式。
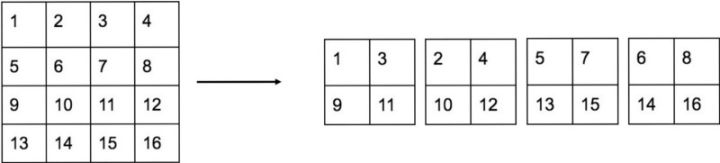
- Fine-Grained Features: 1313的特征图对于小物体来说太小了,所以需要增加特征图信息。这里通过passthrough来实现,即将最后一个pooling前2626512的特征图转换为1313*2048的特征图,然后再与pooling后的特征吃concat,作为后续检测的输入。转换方式如下图。
- 多尺寸训练
- Faster
- Darknet-19: vgg很好,但太复杂了,所以设计了Darknet-19。
- 训练过程:
- 先用224224在ImageNet上训练分类模型,在用448448fine-tune已经获取的模型。
- 训练检测模型的时候,channels是 num_priors(5num_classes)
- Darknet-19: vgg很好,但太复杂了,所以设计了Darknet-19。
- Stronger:主要就是介绍如何一次分类9000类,不太感兴趣。
- 损失函数就放上参考文献中的截图:


1.3. Yolo v3
- 参考资料:
- 素质四连
- 要解决什么问题?
- 将一些新的技术添加到yolo中。
- 用了什么方法解决?
- 在预测标签时,使用binary cross-entropy而不是softmax。这样在预测多标签任务时很有用。
- 使用了 Multi-scale predict,类似于SSD,就是在多个尺寸的特征图上都分别检测bbox。
- 使用了新的darknet结构。
- 效果如何?
- 又快又好。
- 还存在什么问题?
- 不太清楚,就感觉很好。
- 要解决什么问题?
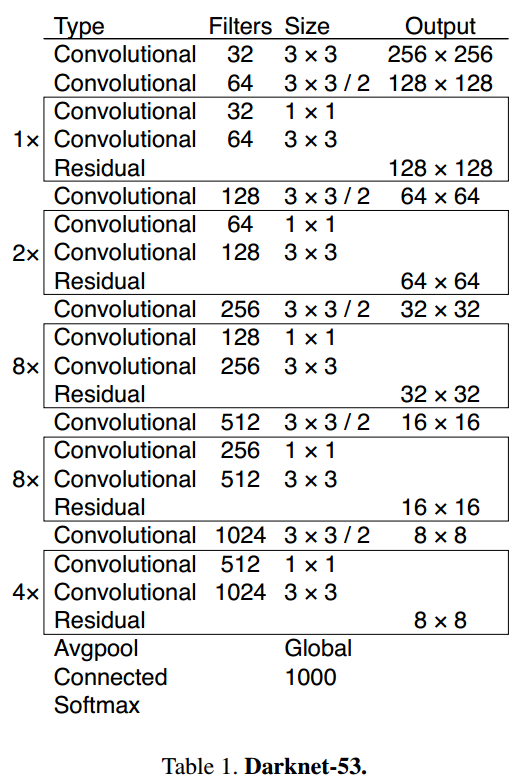
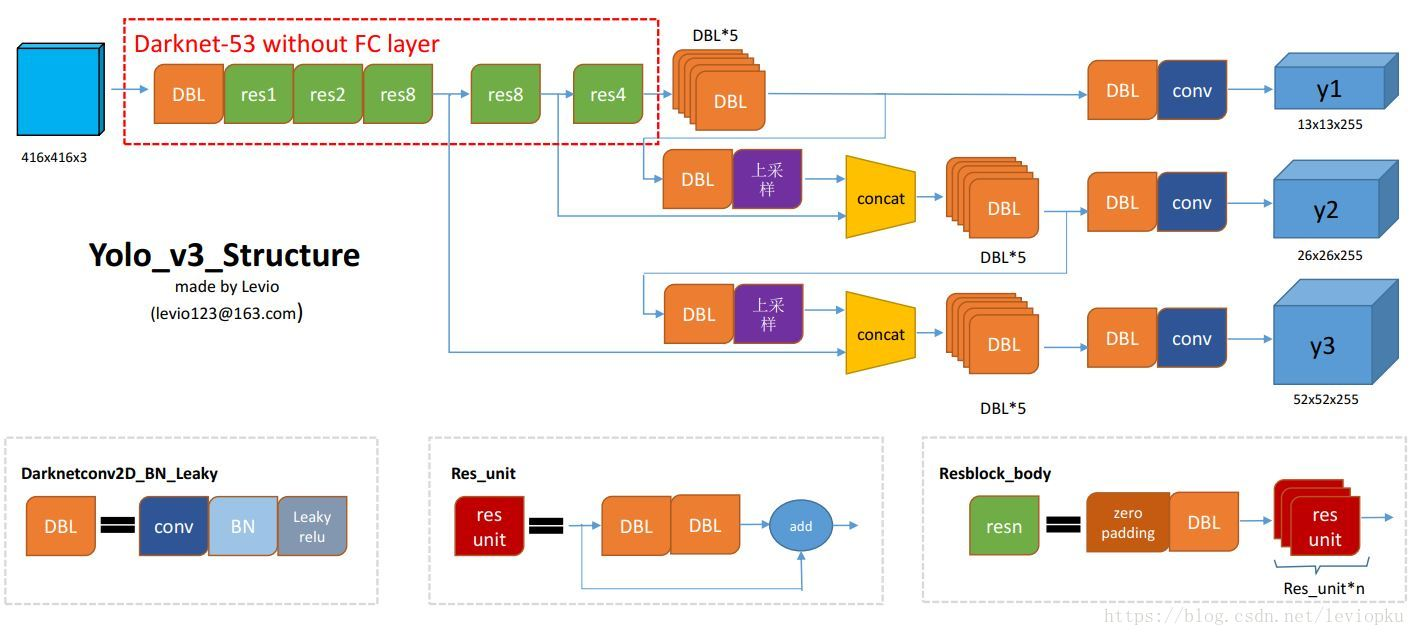
2. DarkNet实践
2.1. 安装
- 安装方法:进入 darknet 文件夹后直接输入
make命令即可。 - 默认安装版本是:CPU版,且不使用OpenCV。
- GPU版本:修改
Makefile文件中的内容GPU=1。 - OpenCV版本:
- 方法:修改
Makefile文件中OPENCV=1 - 作用:可以使用摄像头,以及所有OpenCV支持的图片、视频文件(本来只支持部分格式)。
- 方法:修改
- 采坑:在安装OpenCV版本时老是出现问题。最后重新安装OpenCV解决,但安装时要注意以下几点:
- 注意OpenCV的版本,建议不要使用3.4.1(存在已知错误),其他版本应该可以。我用当前最新的 3.4.7 成功了。
- 需要修改OpenCV的安装文件
CMakeLists.txt,设置OCV_OPTION(OPENCV_GENERATE_PKGCONFIG "Generate .pc file for pkg-config build tool (deprecated)" ON ) - 在安装成功后可能还需要进一步处理,参考这里,即。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 修改 /etc/ld.so.conf 文件
# 即 sudo vim /etc/ld.so.conf
# 添加内容
include /etc/ld.so.conf.d/*.conf
include /usr/local/lib
# 保存并运行
sudo ldconfig
# 修改 /etc/bash.bashrc 文件
# 即 sudo vim /etc/bash.bashrc
# 文末添加
PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
export PKG_CONFIG_PATH
# 最后更新配置文件
source /etc/bash.bashrc
2.2. 直接默认命令
- 方式就是使用
./darknet来进行目标检测。 - 在 这里 有详细实例。
- 举例:
1
2
3
4
5
6
7
8摄像头
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights -c 0
检测视频
./darknet detector demo cfg/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights test.mp4
检测结果保存到视频
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights test.mp4 -out_filename out.avi
2.3. 调用Python接口
- 主要源码位于 这里 中。
- 有几个要点:
- DarkNet接口中已经进行了NMS,不需要再自己手动处理。
- 输入图像是RGB。
- 脚本中还提供了在图上画bbox的代码。
2.4. V100 测试 YoloV3
| 环境 | 推理性能(视频读取+图像预处理+检测) | 检测时间(ms) |
|---|---|---|
| DarkNet | 71.62fps/14.0ms | 9.3 |
| TVM + cudnn | 40.88fps/24.5ms | 18.8 |
| TVM + Auto-tuned | 43.95fps/22.8ms | 17.4 |
| TensorFlow | 28.03fps/36.8ms | 28.0 |
| TensorFlow + TensorRT | 28.24fps/35.4ms | 25.6 |